Project Description
Project Background
Pharmacovigilance monitors the drugs in the market to ensure that unexpected effects (Adverse Drug Events or ADEs) are immediately identified and actions are taken to minimize their harm.
Patients have started reporting such ADEs on social media, health forums and similar outlets instead of using formal reporting methods. Given the need to monitor these sources for pharmacovigilance purposes, systems for the automatic extraction of ADE are becoming an important research topic in Artificial Intelligence and in particular in the field of Natural Language Processing. Recent Shared Tasks on the topic of ADE extraction have attracted numerous focused contributions.
Our research group has been working on an architecture for automatic ADE extraction from social media texts, with a focus on maintaining high performances on different text typologies (from short and noisy tweets to long and more formal medical forum posts).
Our latest experiments lead us to reach the top of the leaderboard in one of the most relevant and active Shared Tasks in this field: SMM4H'19 (Social Media Mining for Health, 2019).
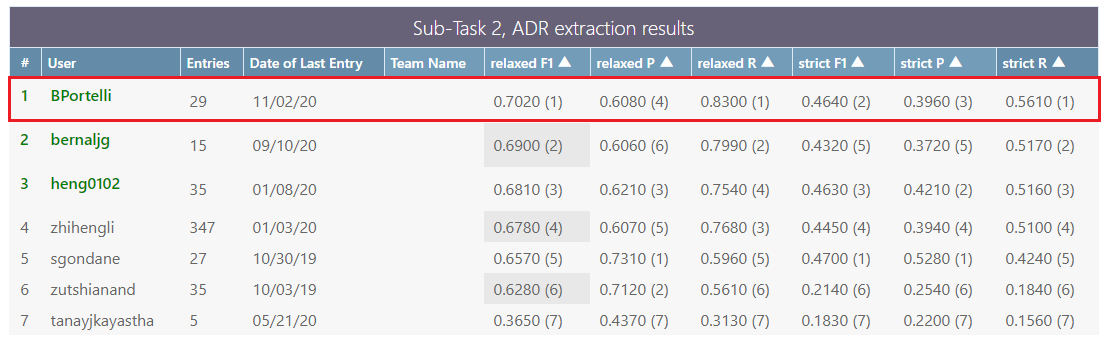
(Public Leaderboard available here, under the section "Sub-Task 2: ADR extraction, Post-Evaluation")
Full System Architecture
The full System behind this website consists of a module dedicated to data collection and five separate modules dedicated to data processing: Localization, Hashtag Analysis, URL Analysis, Sentiment Analysis, Symptom Extraction.
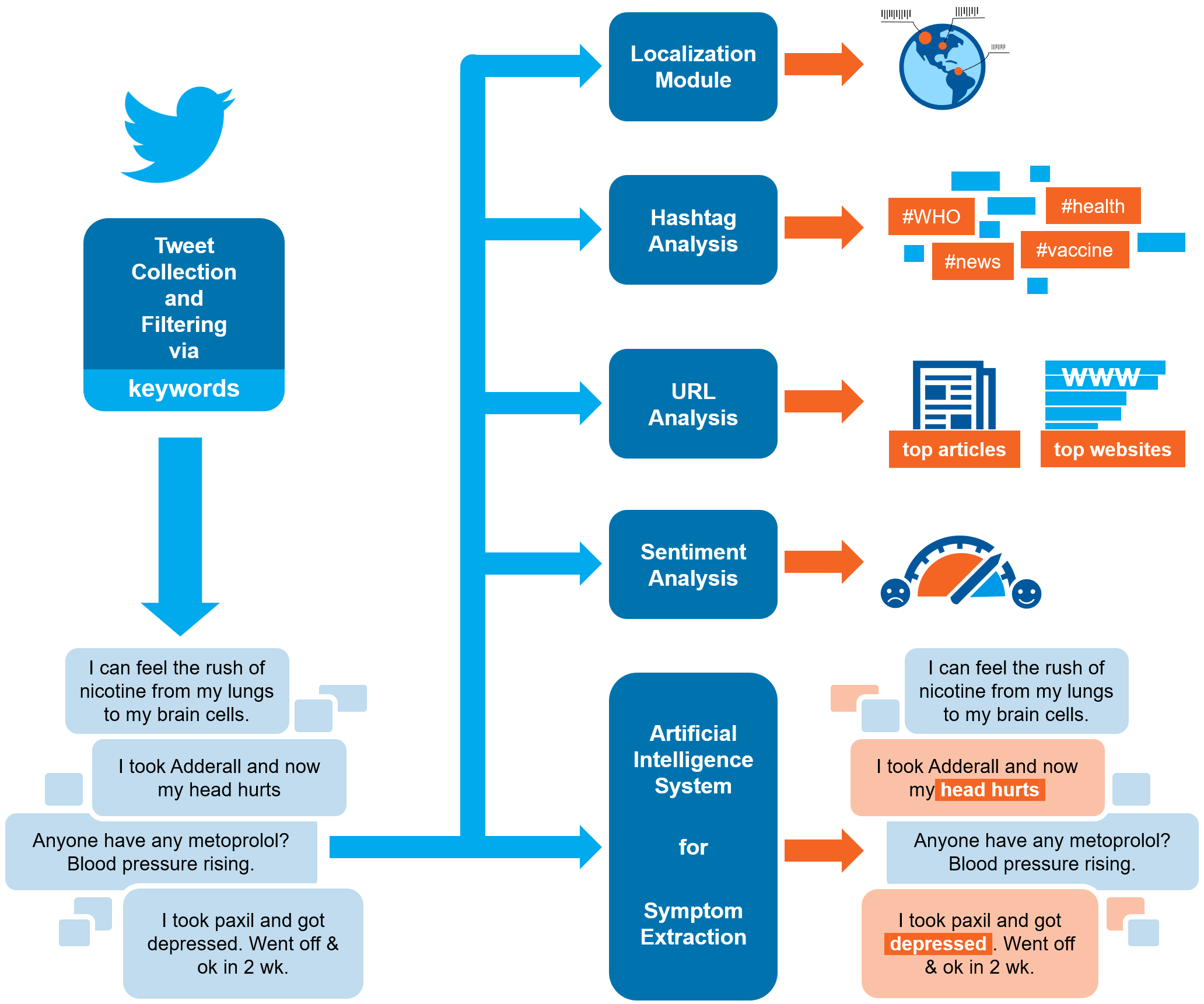
Data Collection
Tweets are collected using the Twitter API. The query is composed by a set of COVID-related keywords combined with the names of the vaccines we are currently monitoring (Pfizer, Astrazeneca and Moderna). Tweets are also filtered by language, keeping English texts only. We aim to remove this limitation in the near future, adding multi-language support (you can help us now by donating to improve our website). We collect and store only the information needed for the following processing steps.
Data collection and data processing take place daily, so that the information displayed on the website is always up-to-date.
Localization Module
It allows to track the geographical origin of the tweet, visualizing which countries are more involved in the discussion about the vaccines.
The geolocation is extracted directly from the tweet whenever it is possible. If precise geolocation is not available the module attempts to reconstruct it using the user’s “location” (reported in the user’s profile). This kind of information is free text provided by the user and may contain imaginative terms or inexistent locations. The module relies on thorough preprocessing and cleaning steps and the aid of the Google Maps services to determine the most accurate match for the location.
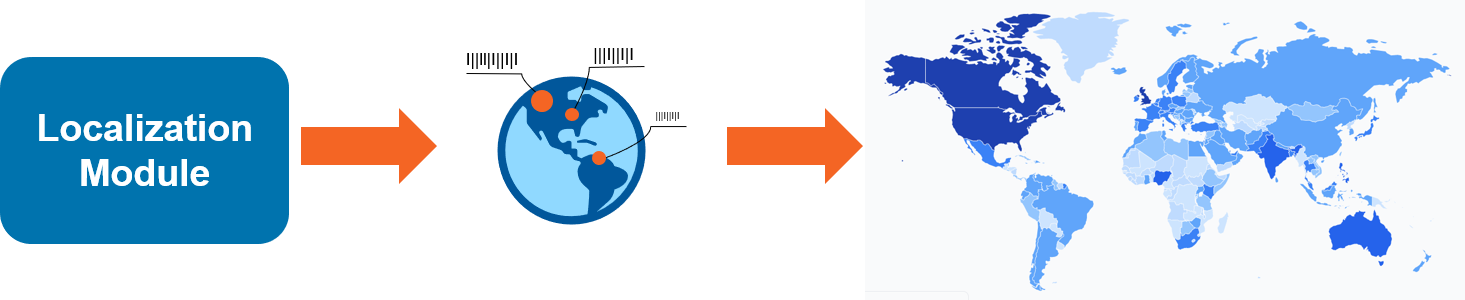
Information is displayed on a world map in different shades of colour: the larger the number of tweets, the darker the color (the scale is exponential).
Hashtag Analysis
Hashtags are extracted from the most recent tweets (last 7 days).
We decided to automatically remove a curated selection of hashtags, considered to be of low information content. In particular we remove all hashtags containing the name of the vaccines that we are tracking (e.g. #pfizer, #moderna, #biontech, …), words directly related to the Covid-19 (e.g. #covid, #coronavirus, #covidvaccine, …) and the ones containing “#vaccine” only.

Information displayed on the website shows the most frequently used hashtags.
URL Analysis
This module collects all URLs shared in the latest tweets (last 7 days).
URLs are used both in their full form and considering their domain only. Unique URLs and domains are counted and used to provide two different kinds of information: the single most most shared web-pages and the most popular sources of information.
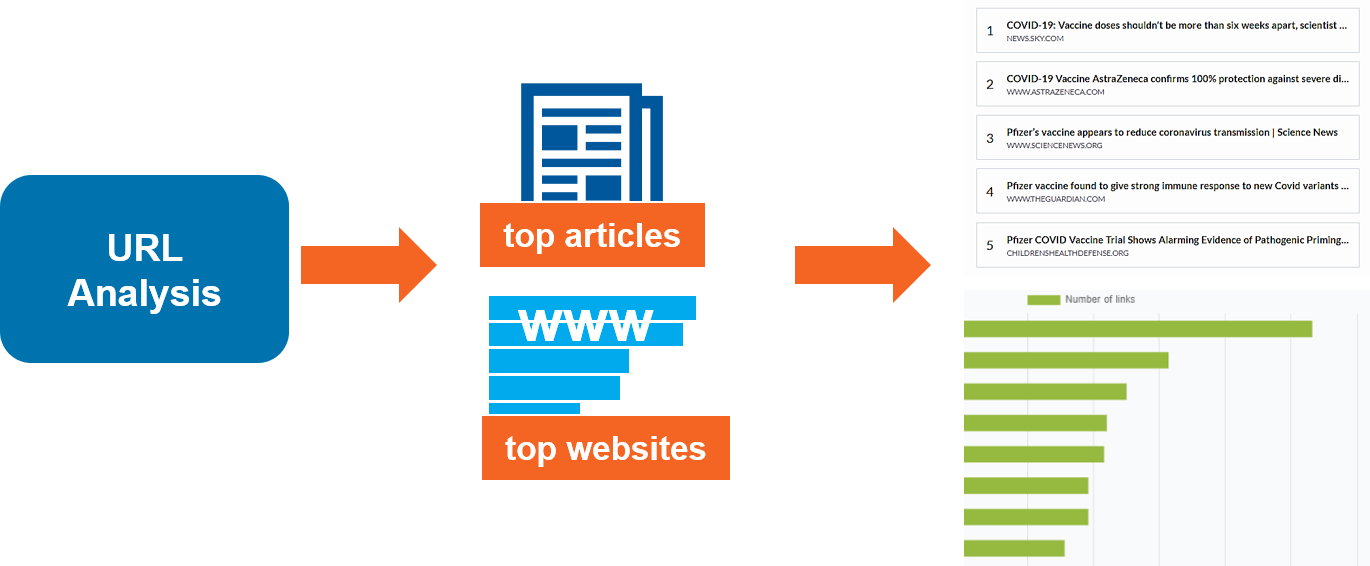
The information on URLs are produced taking into consideration the most recent tweets only, in order to reflect the impact of the most recent news.
Sentiment Analysis
What is the attitude of the users when sharing their opinions of the vaccines and their possible side effect? In order to understand the general sentiment of the crowd when talking about the vaccines, we employ a sentiment analysis module which is specialized in social media texts.
Whenever a tweet is displayed on screen you can see an indication of its sentiment: is the user reporting facts, expressing distress or showing a positive attitude?

Symptom Extraction
This module extracts all possible symptoms which are being discussed in the tweets. The data are then aggregated and visualized on the website as a Word Cloud, which can be filtered by vaccine.
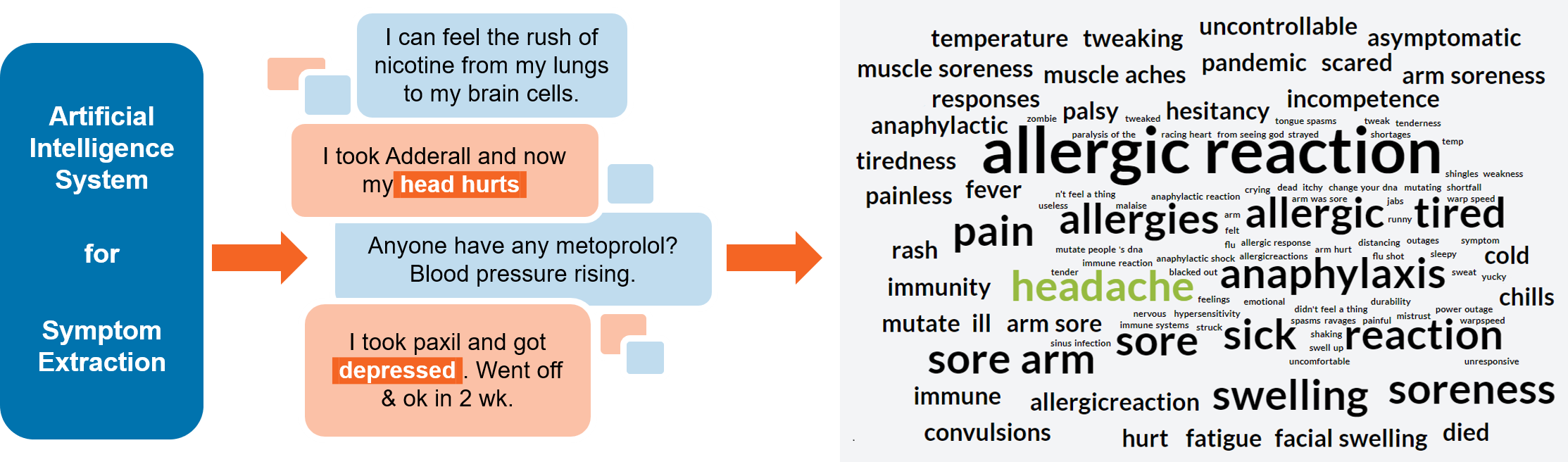
It employs neural neural network architecture based on SpanBERT and Conditional Random Fields, trained on the Adverse Event Detection dataset of the SMM4H 2019 Shared Task . It represents the current state of the art on the Shared Task. More information about it can be found in the related paper: Improving Adverse Drug Event Extraction with SpanBERT on Different Text Typologies.
This model is able to identify tweets containing potential adverse events and to highlight the mention of the symptoms.
Limitations: this model has no ability to verify the reliability of the tweets and it was trained solely on the data provided during the shared task. Also note that the results of the extraction are not fact-checked by humans.
The code for the algorithm and the processed data are available for research purposes.
Contact us at: nlp4ade@gmail.com
Team
Project Developers





Lead Board



Advisory Board


