Descrizione del progetto
Contesto del Progetto
La Farmacovigilanza monitora i farmaci sul mercato per assicurare che gli effetti collaterali inaspettati (in inglese Adverse Drug Events o ADE) siano immediatamente identificati, agendo prontamente per minimizzare i loro danni.
I pazienti hanno cominciato a riportare tali ADE sui social media, su forum dedicati alla salute e su altri canali digitali invece di utilizzare metodi formali. È quindi sorta la necessità di monitorare tali fonti di informazione a fini di farmacovigilanza. Lo sviluppo di sistemi per l’estrazione automatica degli ADE è diventato un importante argomenti di ricerca nel campo dell’Intelligenza Artificiale e in particolare dell’Analisi del Linguaggio Naturale. Recenti competizioni pubbliche (Shared Task) su questo argomento hanno generato ulteriore interesse e spinto la creazione di molto contributi.
Il nostro gruppo di ricerca ha lavorato alla creazione di un’architettura per l’estrazione automatica di ADE da testi di social media, focalizzandosi sull’abilità di ottenere alte performance su diverse tipologie di testi (a partire dai tweet, corti e sconnesse, arrivando ai post sui forum medici, più lunghi e formali).
I nostri recenti esperimenti ci hanno portato in cima alla classifica di uno dei più importanti Shared Task in questo ambito: SMM4H'19 (Social Media Mining for Health, 2019).
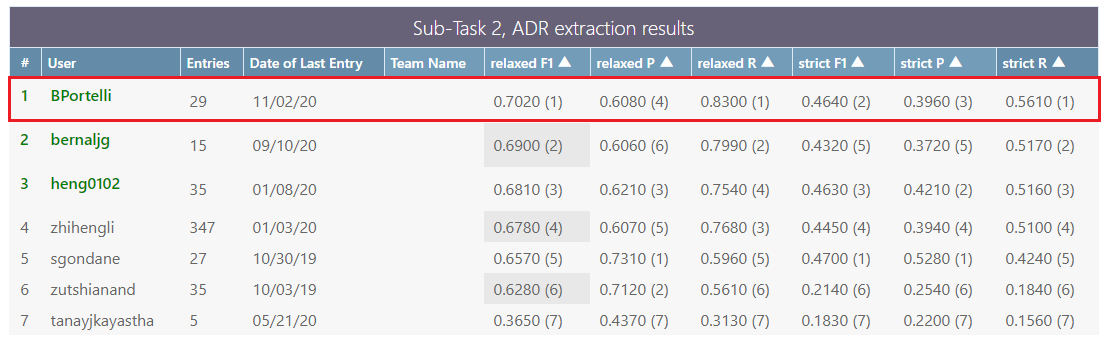
(Classifica pubblica consultabile qui, sotto la sezione “Sub-Task 2: ADR extraction, Post-Evaluation”)
Architettura del Sistema
Il sistema sul quale si basa questo sito web consiste di un modulo dedicato alla raccolta dei dati e cinque moduli indipendenti dedicati alla loro analisi: Localizzazione, Analisi degli Hashtag, Analisi degli URL, Analisi del Sentiment, Estrazione di Sintomi.
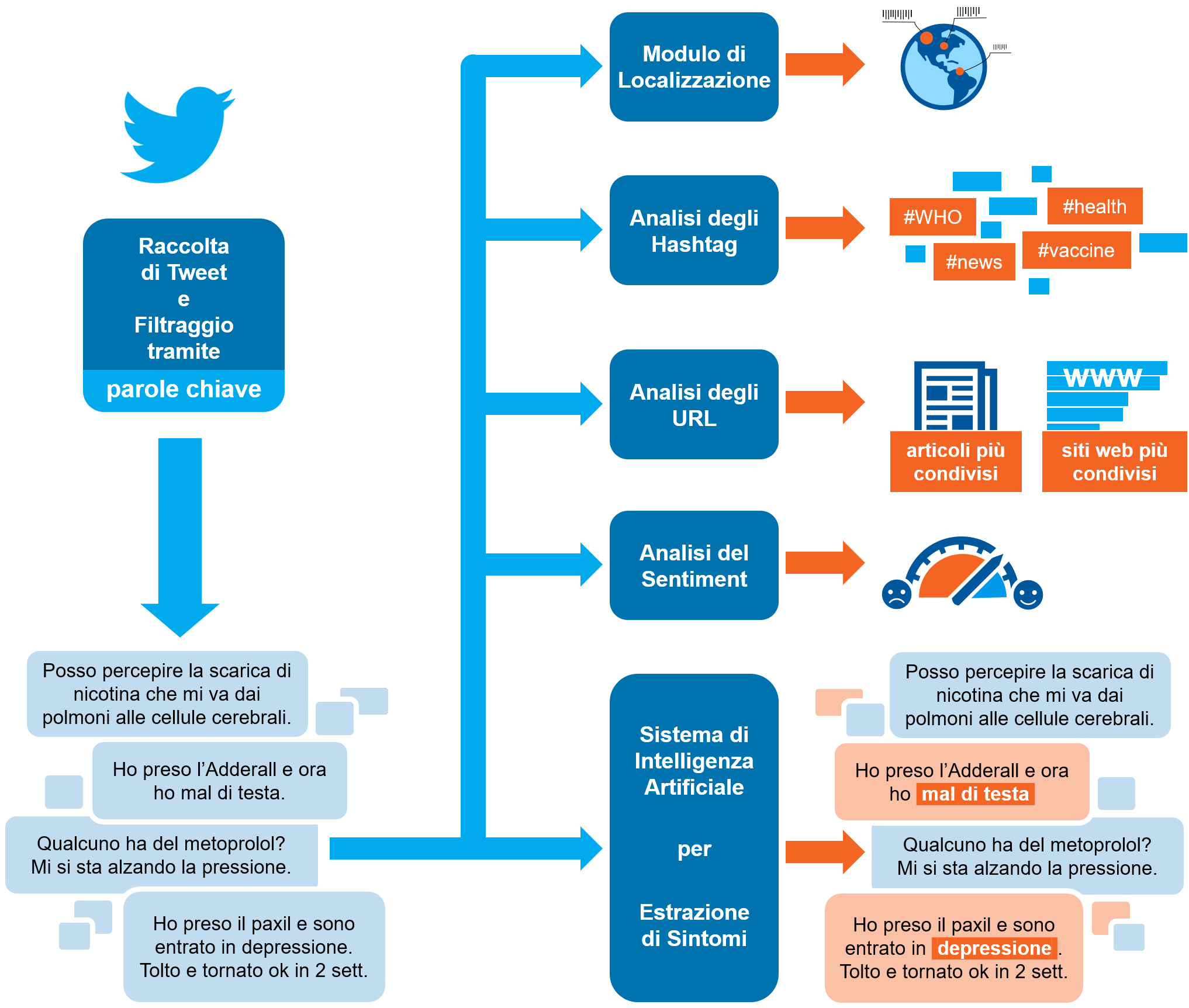
Raccolta Dati
I tweet sono raccolti usando l’API ufficiale di Twitter. La query di ricerca è composta da un insieme di parole chiave inerenti il COVID, combinate con i nomi dei vaccini che stanno venendo monitorati al momento (Pfizer, Astrazeneca e Moderna). I tweet sono anche filtrati per lingua, mantenendo solo quelli in lingua inglese. Il nostro gruppo di ricerca mira e rimuovere questa limitazione nel futuro prossimo, aggiungendo un supporto multi-lingua (puoi aiutarci ora con una donazione per migliorare il sito). Raccogliamo e salviamo solo le informazioni necessarie per le analisi effettuate nei passaggi successivi.
La raccolta e l’analisi dei dati viene effettuata su base giornaliera. In questo modo le informazioni mostrate sul sito sono sempre aggiornate.
Modulo di Localizzazione
Permette di tracciare l’origine geografica del tweet, visualizzando quali Stati sono più coinvolti nella discussione sui i vaccini.
La geolocalizzazione è estratta direttamente dal tweet quando possibile. Se una geolocalizzazione precisa non è disponibile, il modulo tenta di ricostruirla usando la “posizione” dell’utente (riportata nel profilo dell’utente stesso). Questo tipo di informazione è testo libero fornito dall’utente e potrebbe contenere termini fantasiosi o luoghi inesistenti. Questo modulo fa affidamento su un’accurata pulizia e pre-elaborazione dei testi, unita ai servizi offerti da Google Maps, per determinare la corrispondenza più accurata possibile per ogni luogo.
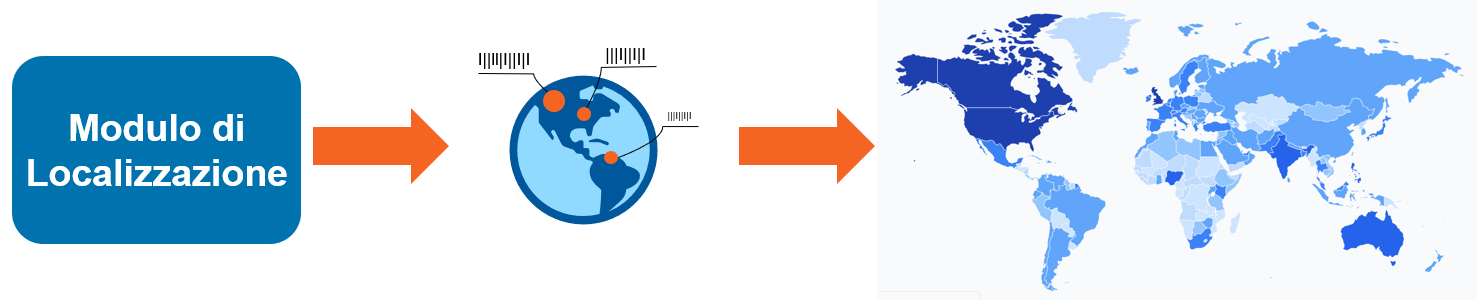
Le informazioni sono visualizzate su una mappa del mondo con diverse sfumature di colore: più grande è il numero di tweet, più scuro è il colore dello stato (la scala è esponenziale).
Analisi degli Hashtag
Gli hashtag sono estratti dai tweet più recenti (ultimi 7 giorni).
Abbiamo deciso di rimuovere automaticamente un insieme selezionato di hashtag che sono considerati di basso contenuto informativo. In particolare rimuoviamo tutti gli hashtag contenti il nome dei vaccini che stiamo monitorando (es. #pfizer, #moderna, #biontech, …), parole strettamente collegate al Covid-19 (es. #covid, #coronavirus, #covidvaccine, …) e quelli che contengono semplicemente la parola vaccino (#vaccine).

Le informazioni sul sito mostrano quali sono gli hashtag usati più frequentemente.
Analisi degli URL
Questo modulo raccoglie tutti gli URL condivisi nei tweet più recenti (ultimi 7 giorni).
Gli URL sono usati sia nella loro forma completa che tenendo conto soltanto del loro dominio. Gli URL e i domini univoci vengono contati e usati per fornire due diversi tipi di informazione: le pagine web più condivise e le fonti di informazione più popolari.
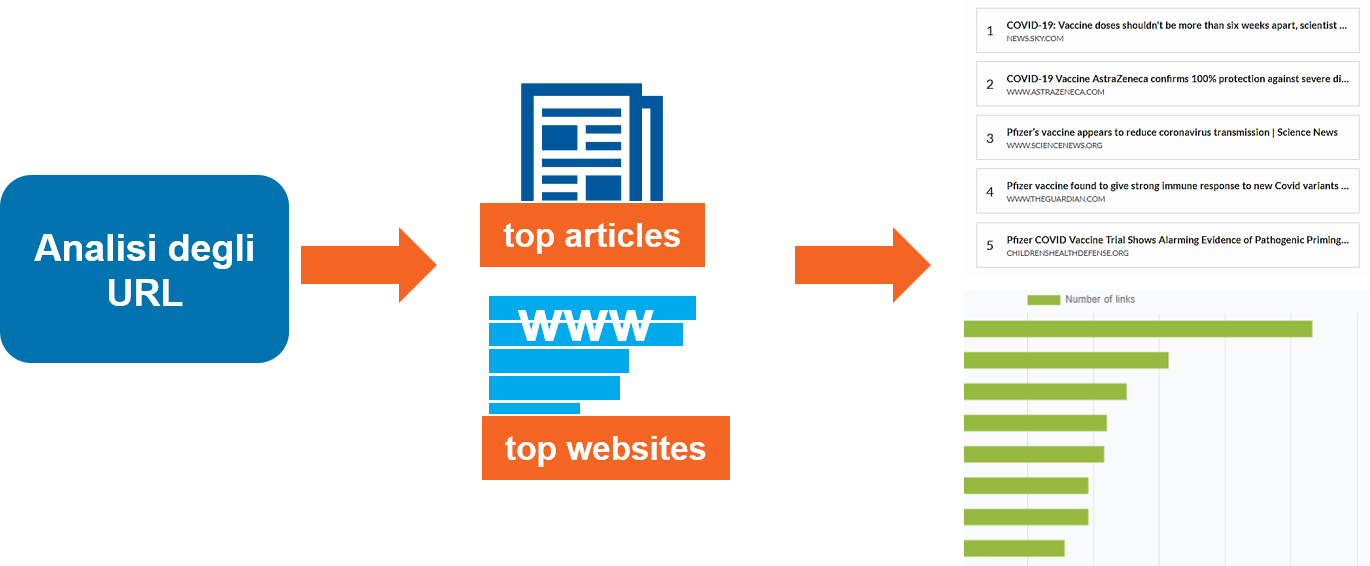
Le informazioni sugli URL vengono prodotte prendendo in considerazione solo i tweet più recenti per riflettere l'impatto delle notizie più recenti.
Analisi del Sentiment
Qual è la disposizione d'animo degli utenti quando condividono le loro opinioni sui vaccini e i loro possibili effetti collaterali? Per comprendere il sentiment generale della popolazione di utenti che parlano di vaccini utilizziamo un modulo di analisi del sentiment, specializzato per l’analisi di testi provenienti dai social media.
Ogni volta che un tweet viene mostrato all’interno del sito, potete notare un’indicazione del suo sentiment: l’utente sta solo esponendo dei fatti in maniera neutrale, sta esprimendo disappunto oppure sta dimostrando un atteggiamento positivo?

Estrazione dei Sintomi
Questo modulo estrae tutti i possibili sintomi che sono discussi all’interno dei tweet. I dati sono poi aggregati e visualizzati sul sito sotto forma di una "Nuvola di Parole", che può essere filtrata per vaccino.
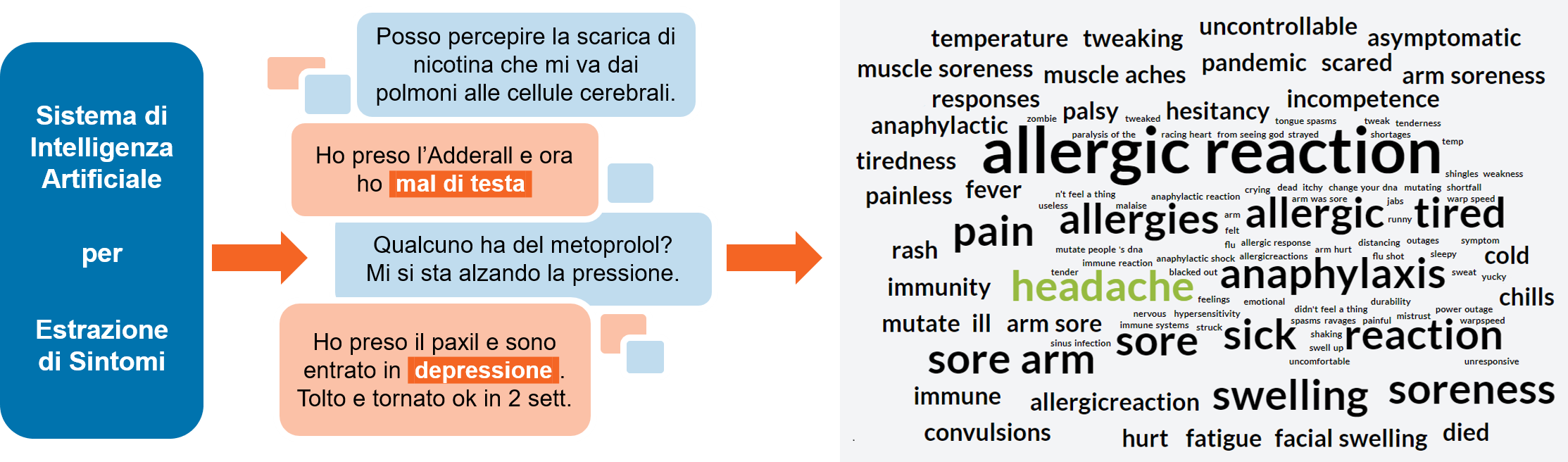
È stata impiegata una architettura basata su reti neurali, costruita a partire da un modulo SpanBERT e un Conditional Random Field. L’architettura è addestrata sul dataset di Adverse Event Detection (individuazione di effetti avversi) della competizione SMM4H 2019 Shared Task. Al momento rappresenta lo stato dell’arte in questa competizione. Per maggiori informazioni rimandiamo all’articolo relativo all’architettura utilizzata: Improving Adverse Drug Event Extraction with SpanBERT on Different Text Typologies.
Questo modello è in grado di identificare i tweet che contengono potenziali eventi avversi ed evidenziare i sintomi menzionati al loro interno.
Limitazioni: questo modello non è in grado di verificare la veridicità o l’affidabilità del tweet, ed è stato addestrato utilizzando esclusivamente i dati forniti durante la competizione. Teniamo inoltre a ricordare che i risultati dati dall’estrazione non sono controllati da esperti umani.
Il codice dell’algoritmo e i dati sono disponibili per fini di ricerca.
Potete contattarci qui: nlp4ade@gmail.com
Team
Project Developers





Lead Board



Advisory Board


