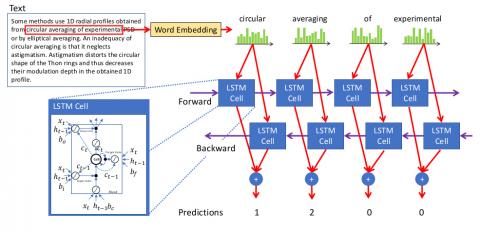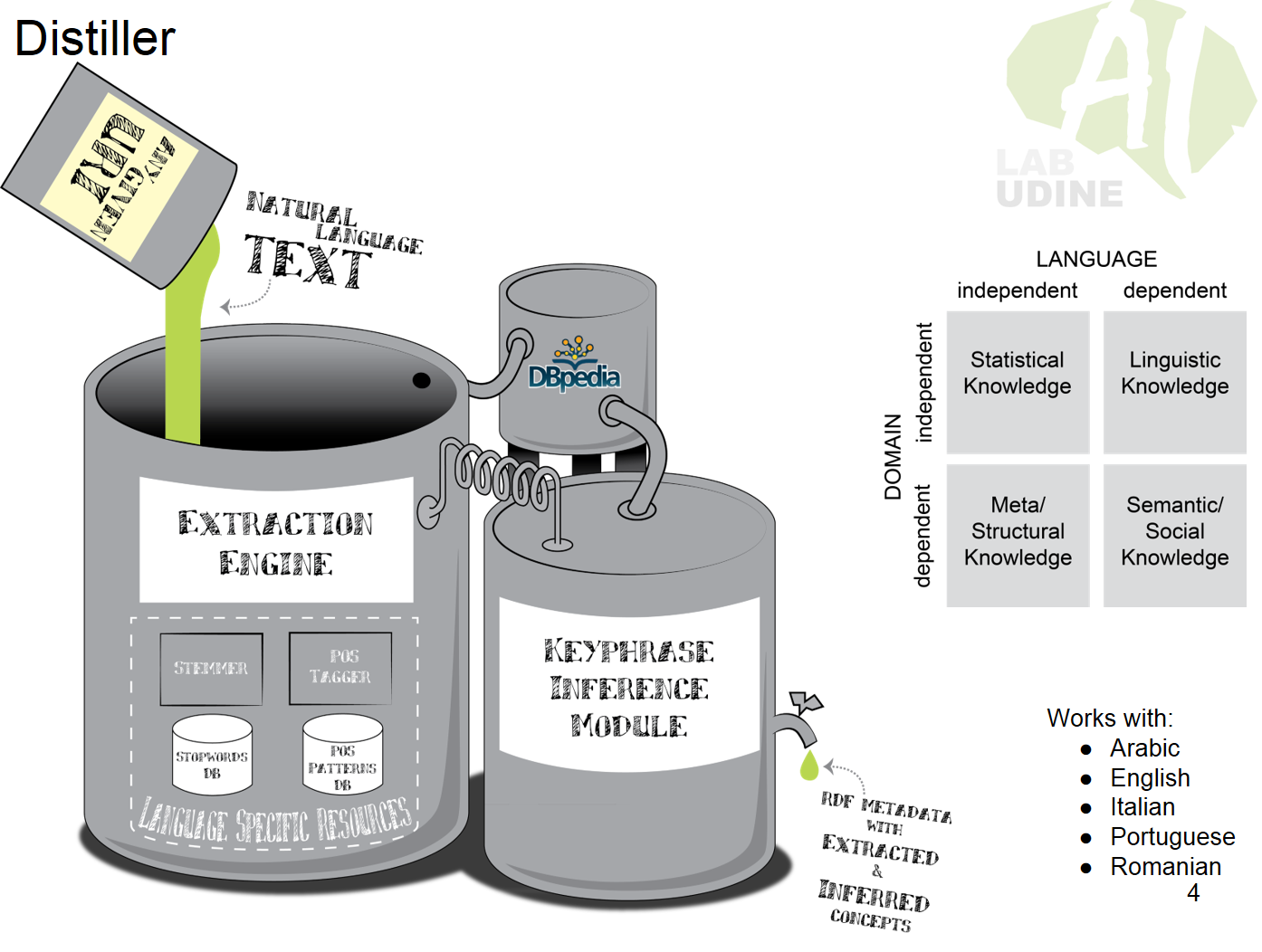
Keyphrases (KPs) are phrases that “capture the main topic discussed on a given document”. More specifically, KPs are phrases typically one to five words long that appear verbatim in a document, and can be used to briefly summarize its content. The task of finding such KPs is called Automatic Keyphrase Extraction (AKE). Recently, AKE has received a lot of attention, because it has been successfully used in many natural language processing (NLP) tasks, such as text summarization, document clustering, or non-NLP tasks such as social network analysis or user modeling. AKE approaches have been also applied in Information Retrieval of relevant documents in digital document archives which can contain heterogeneous types of items, such as books articles, papers etc. However, given the wide variety of lexical, linguistic and semantic aspects that can contribute to define a keyphrase, it difficult to design hand-crafted feature, and even the best performing algorithms hardly reach F1-Scores of 50% on the most common evaluation sets. […]