We’re up & running!

Today we’re launching our new theme!
Local Pyramidal Descriptors for Image Recognition

In this paper we present a novel method to improve the flexibility of descriptor matching for image recognition by using local multiresolution pyramids in feature space. We propose that image patches be represented at multiple levels of descriptor detail and that these levels be defined in terms of local spatial pooling resolution. Preserving multiple levels of detail in local descriptors is a way of hedging one’s bets on which levels will most relevant for matching during learning and recognition. We introduce the Pyramid SIFT (P-SIFT) descriptor and show that its use in four state-of-the-art image recognition pipelines improves accuracy and yields state-of-the-art results. Our technique is applicable independently of spatial pyramid matching and we show that spatial pyramids can be combined with local pyramids to obtain further improvement. We achieve state-of-the-art results on Caltech-101 (80.1%) and Caltech-256 (52.6%) when compared to other approaches based on SIFT features over intensity images. Our technique is efficient and is extremely easy to integrate into […]
Human action categorization in unconstrained videos

Building a general human activity recognition and classification system is a challenging problem, because of the variations in environment, people and actions. In fact environment variation can be caused by cluttered or moving background, camera motion, illumination changes. People may have different size, shape and posture appearance. Recently, interest-points based models have been successfully applied to the human action classification problem, because they overcome some limitations of holistic models such as the necessity of performing background subtraction and tracking. We are working at a novel method based on the visual bag-of-words model and on a new spatio-temporal descriptor. First, we define a new 3D gradient descriptor that combined with optic flow outperforms the state-of-the-art, without requiring fine parameter tuning. Second, we show that for spatio-temporal features the popular k-means algorithm is insufficient because cluster centers are attracted by the denser regions of the sample distribution, providing a non-uniform description of the feature space and thus failing to code other informative […]
GOLD: Gaussians of Local Descriptors for image representation
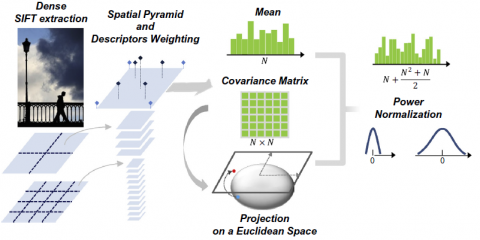
The Bag of Words paradigm has been the baseline from which several successful image classification solutions were developed in the last decade. These represent images by quantizing local descriptors and summarizing their distribution. The quantization step introduces a dependency on the dataset, that even if in some contexts significantly boosts the performance, severely limits its generalization capabilities. Differently, in this paper, we propose to model the local features distribution with a multivariate Gaussian, without any quantization. The full rank covariance matrix, which lies on a Riemannian manifold, is projected on the tangent Euclidean space and concatenated to the mean vector. The resulting representation, a Gaussian of Local Descriptors (GOLD), allows to use the dot product to closely approximate a distance between distributions without the need for expensive kernel computations. We describe an image by an improved spatial pyramid, which avoids boundary effects with soft assignment: local descriptors contribute to neighboring Gaussians, forming a weighted spatial pyramid of GOLD descriptors. In […]