Video event classification using bag-of-words and string kernels

The recognition of events in videos is a relevant and challenging task of automatic semantic video analysis. At present one of the most successful frameworks, used for object recognition tasks, is the bag-of-words (BoW) approach. However it does not model the temporal information of the video stream. We are working at a novel method to introduce temporal information within the BoW approach by modeling a video clip as a sequence of histograms of visual features, computed from each frame using the traditional BoW model. The sequences are treated as strings where each histogram is considered as a character. Event classification of these sequences of variable size, depending on the length of the video clip, are performed using SVM classifiers with a string kernel (e.g using the Needlemann-Wunsch edit distance). Experimental results, performed on two domains, soccer video and TRECVID 2005, demonstrate the validity of the proposed approach. Related Publication: Ballan, L., M. Bertini, A. Del Bimbo, and G. Serra, “Video Event […]
A SIFT-based forensic method for copy-move detection
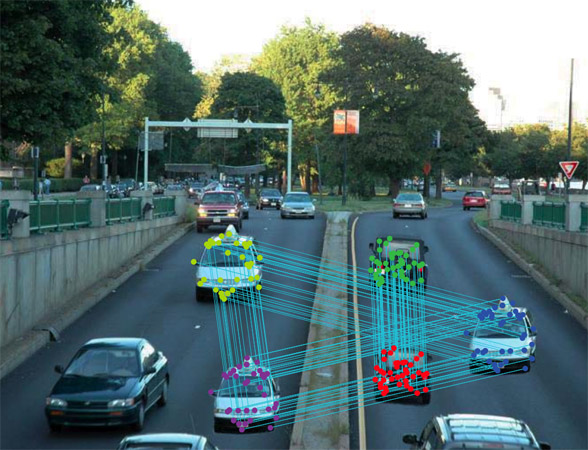
In many application scenarios digital images play a basic role and often it is important to assess if their content is realistic or has been manipulated to mislead watcher’s opinion. Image forensics tools provide answers to similar questions. We are working on a novel method that focuses in particular on the problem of detecting if a feigned image has been created by cloning an area of the image onto another zone to make a duplication or to cancel something awkward. The proposed approach is based on SIFT features and allows both to understand if a copy-move attack has occurred and which are the image points involved, and, furthermore, to recover which has been the geometric transformation happened to perform cloning, by computing the transformation parameters. In fact when a copy-move attack takes place, usually an affine transformation is applied to the image patch selected to fit in a specified position according to that context. Our experimental results confirm that the […]
Vidi Video: Interactive semantic video search with a large theasurus of machine-learned audio-visual concepts
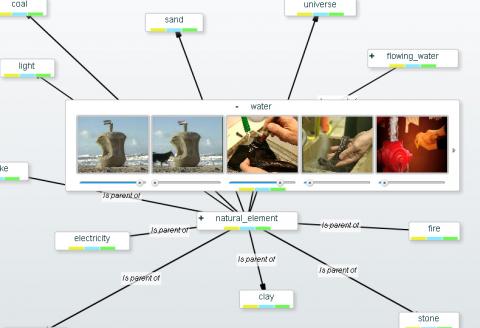
Video is vital to society and economy. It plays a key role in the news, cultural heritage documentaries and surveillance, and it will soon be the natural form of communication for the Internet and mobile phones. Digital video will bring more formats and opportunities and it is certain the the consumer and the professional need advanced storage and search technology for the management of large-scale video assets. This project takes on the challenge of creating a substantially enhanced semantic access to video, implemented in a search engine. Vidi Video will boost the performance of video search by forming a 1000 element of thesaurus detecting instances of audio, visual or mixed-media content. The consortium presents excellent expertise and resource: the machine learning with active 1-class classifiers to minimize the need for annotated examples is lead by the University of Surrey, UK. Video stream processing is lead by Centre For Research and Techonolgy Hellas, Greece. Another component is audio event detection, lead by INESC-ID, Portugal. Visual image processing is lead by […]
Metric target tracking

In the context of visual surveillance one of the most important problem is the observation of human activity. This problem is greatly simplified when metric information can be computed. The goal of this project is to development and test new algorithms to determine metric information automatically by observing the scene. A system to find the metric information by tracking a moving person on a ground has been developed. This algorithm consists in a method for calibration of two cameras based on features of a moving person in their common field of view. Only the image of foot and head locations are used. In fact these points and their geometric relationship between cameras give enough information to find their relative position and orientation and the internal parameters of each camera, the focal length and the principal point. In particular the proposed method works under the assumption that the scene needs to be modeled well with a dominant ground plane and the […]