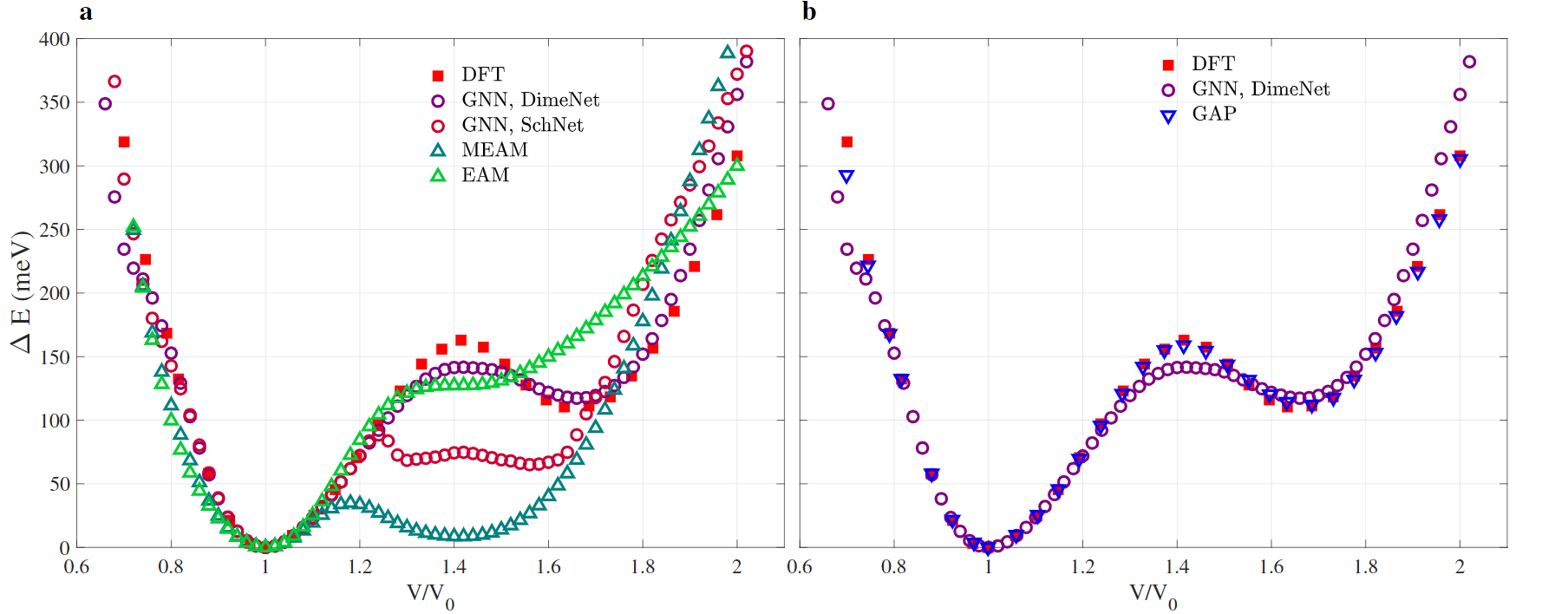
The useful, macroscopic characteristics of materials depend on their microscopic structure. Which is basically a very regular graph. At AILAB we applied Graph Neural Networks to the analysis of materials at atomic scale. After an extended testing phase, we obtained good results in the prediction of a set of physical properties such as Energy-Volume relation, Bain path curve, and evaluation of point and surface defects. This is a new research topic in Deep Learning, and will become more and more important in the near future thanks to its flexibility. Have a look at our arxiv paper Research Group: Lorenzo Cian (AILAB-Udine) Giuseppe Lancioni (AILAB-Udine) Lei Zhang (University of Groningen) Mirco Ianese (AILAB-Udine) Nicolas Novelli(AILAB-Udine) Giuseppe Serra (AILAB-Udine) Francesco Maresca (University of Groningen)
